
Before considering how to design and create relational databases, we can gain an understanding of many relational database concepts by learning how to access their data. In this module, we begin discussing the Structured Query Language (SQL), which is the English-like interface to relational databases. We study standard SQL in general and the SQL product MySQL in particular. Unless otherwise indicated, a command is standard SQL and is executable in MySQL. A very good book on the subject is MySQL & mSQL by R. J. Yarger, G. Reese, and T. King, O’Reilly Publ., Sebastopol, CA, 1999. The following are links to other SQL tutorials and references:
To start MySQL on a UNIX system, type mysql to launch the command version and xmysql for the GUI version.
To indicate which existing database we use, we employ the use statement, such as follows:
use BioStudy;
As always, English comments to document code are important. In MySQL, a comment line begins with a number sign (#) or semicolon (;) and continues to the end of the line, such as follows:
# SQL to access a database for Physics
# laboratory experiments
It is easy to forget the name of a database or its structure. The show statement provides a way for us to refresh our memories. Once in MySQL, to obtain a listing of a databases, we write
show databases;
Within a database, we get a listing of the tables, as follows:
show tables;
To display the relations in database PsyDB that we are not using, we issue the statement
show tables from PsyDB;
The following statements display table LabSection's columns with their data types and the table's keys:
show columns from LabSection;
show keys from LabSection;
The most common SQL statement is select, which allows us to query the database, performing the select, project, and join operations. Suppose the relation CurrentBioStudy has a primary key subject of type string with values such as 'SubjectA'. Because subject is the key, each row must have a value for subject, and that value must be unique. The other attributes, RhFactor and BloodType, have enumeration types. The possible values of RhFactor are '+' and '-', while possible blood types for the study are 'M', 'N', and 'MN'. With the key subject underlined, the schema for CurrentBioStudy is as follows:
BioStudy_schema = (subject:string, RhFactor:{+, -}, BloodType:{M, N, MN})
An alternate form of the schema does not specify types of the attributes but gives the table organization, as follows:
subject RhFactor BloodType
In a select command, we use the where clause to indicate particular row(s). To view the RhFactor of SubjectA in the CurrentBioStudy table, with apostrophes surrounding the string 'SubjectA', we have the following statement:
select RhFactor
from CurrentBioStudy
where subject = 'SubjectA';
The requested field value (+) appears with the name of the field, such as follows:
+----------+
| RhFactor |
+----------+
| + |
+----------+
To discover all rows where data is missing from a column, such as RhFactor, we use the constant value null, which means "no data." As the following statement shows, we do not put apostrophes around null:
select subject
from CurrentBioStudy
where RhFactor = null;
Any relational operator (=, !=, <, <=, >, >=) is permissible for comparisons in a where clause. We can also use the logical connectors (not, or, and), bitwise operators (|, &, <<, >>), and arithmetic operators (+, -, *, /, %) of C++, as well as parentheses.
Example 1. Suppose table ChemExperiment of a chemical database has the following organization:
| ExpNumber | SoluteMass | SolventName | SolventMass | FP |
To display the experiment number and mass from all benzene tuples where the quantity is greater than 100, we list the attributes with commas separating them and use the relational operator greater than (>) and the logical operator && (or and). The select clause indicates how to project the data, while the where clause designates the tuples to select. The command is as follows:
select ExpNumber, SolventMass
from ChemExperiment
where SolventName = ‘Benzene’ and
SolventMass > 100;
To see an entire row (all columns), we use the wild card * to designate all columns, as follows:
select *
from CurrentBioStudy
where subject = 'SubjectA';
The column names with values for SubjectA appear, as follows:
+----------+----------+-----------+
| subject | RhFactor | BloodType |
+----------+----------+-----------+
| SubjectA | + | M |
+----------+----------+-----------+
If we wish to see all the data in the table, we use * and omit the where clause:
select * from CurrentBioStudy;
The output, which is unordered, might appear as follows:
+----------+----------+-----------+
| subject | RhFactor | BloodType |
+----------+----------+-----------+
| SubjectA | + | M |
| SubjectB | + | N |
| SubjectD | - | M |
| SubjectE | + | |
| SubjectC | - | |
+----------+----------+-----------+
To obtain from ChemExperiment a list of all solvents whose name begins with 'b', 'c', 'd', or 'e', we ask to compare SolventName to 'b' and 'f', as follows:
select SolventName
from ChemExperiment
where SolventName >= ‘b’ and SolventName < 'f';
String comparisons are case-sensitive and must match exactly. However, we can use wildcards of a percent symbol (%) to match any number of characters, even none, and a hyphen (-) to match exactly one character. One caution, however, is that the pattern '%' does not match null, which means "no value." For comparisons using a wildcard, we use xxx like instead of an equals mark. Thus, to find all solvents whose name begins with 'b', we employ the following statement:
select SolventName
from ChemExperiment
where SolventName like 'b%';
To match a patten involving % or -, we type a backslash in front of the symbol. Thus, '57\%' matches the string "57%", and 'web\-accessed' matches the hyphenated words "web-accessed".
Quick Review Questions |
To alphabetize the results, we include the order by clause. For example, consider a student relation, such as follows:
+-----------+-----------+-----------+--------------+
| StudentId | LastName | FirstName | StudentGrade |
+-----------+-----------+-----------+--------------+
| 107 | Davis | George | A |
| 102 | Bolder | Anne | A |
| 103 | Donnovan | Patrick | C |
| 104 | Davis | Kyle | D |
| 105 | d'Antonio| Mary | B |
| 106 | Iseman | Bart | F |
| 101 | Davis | George | C |
+-----------+-----------+-----------+--------------+
We want to alphabetize by the last name. However, if several students have the same last name, we want to alphabetize by their first names. If even they agree, we have the ids appear in sorted order. Although we are displaying all fields, because the output should appear in a different order, we specify the columns, as follows:
select LastName, FirstName, StudentId, StudentGrade
from student
order by LastName, FirstName, StudentId;
Execution of this select statement returns a table, such as the below. "George Davis" with student id 101 occurs before "George Davis" with id 107, and " Kyle Davis" appears after "George Davis".
+-----------+-----------+-----------+--------------+
| LastName | FirstName | StudentId |
StudentGrade |
+-----------+-----------+-----------+--------------+
| Bolder | Anne
| 102 | A
|
| d'Antonio | Mary |
105 | B
|
| Davis | George
| 101 | A
|
| Davis | George
| 107 | C
|
| Davis | Kyle
| 104 | D
|
| Donnovan | Patrick |
103 | C
|
| Iseman | Bart
| 106 | F
|
+-----------+-----------+-----------+--------------+
We also use select to implement join operations. Consider the following organization for three relations in a database:
ChemKnowns:
| KnownCompound | MolecularWeight |
ChemSolvents:
| SolventName | FreezingPoint | Kf |
ChemExperiments:
| ExpNumber | SoluteMass | SolventName | SolventMass | FP |
To obtain a listing of solvents with freezing points from ChemSolvent and molecular weights from ChemKnown, we form the join of the two relations, matching tuples where the SolventName from ChemSolvent and the KnownCompound from ChemKnow agree. In SQL, we employ the select statement, listing both tables and the values that must agree, as follows:
select SolventName, FreezingPoint, MolecularWeight
from ChemSolvent, ChemKnown
where SolventName = KnownCompound;
If only Benzene and p-Dichlorobenzene appear in both tables, the output might
be as follows:
+-------------------+---------------+-----------------+
| SolventName |
FreezingPoint | MolecularWeight |
+-------------------+---------------+-----------------+
| Benzene
| 5.50
| 78.11
|
| p-Dichlorobenzene |
53.00 | 147.00
|
+-------------------+---------------+-----------------+
To obtain the set of tuples where each experiment has data from ChemExperiment matched with the data about its solvent from ChemSolvent, we again join
on the solvent name. However, the column name is SolventName in both
tables. To avoid ambiguity, we employ the dot operator as in C++,
designating the tables and column name, ChemExperiment.SolventName and ChemSolvent.SolventName.
Thus, to obtain the solute mass, solution freezing point (FP), solvent
mass, and solvent constant Kf for Experiment 35, we perform the join as
follows:
select SoluteMass, FP, SolventMass, Kf
from ChemExperiment, ChemSolvent
where ExpNumber = 35 and
ChemExperiment.SolventName = ChemSolvent.SolventName;
MySQL has a number of functions that we can use to obtain values or to specify in a where clause. Table 1 lists aggregate functions that apply to a set of values, such as all data in a column.
Table 1. MySQL aggregate functions on set of values, s
| Function | Meaning |
| avg(s) | Average of values in s |
| count(s) | Number of non-null values in s |
| max(s) | Maximum value in s |
| min(s) | Minimum value in s |
| std(s) | Standard deviation of values in s |
| sum(s) | Sum of values in s |
To find the average week of the semester in which Physics 201 performed the Coefficient of Drag Experiment, we have the following statement:
select avg(DragExpWeek)
from LabSection
where CatalogNumber = 'Phys201';
The database does not include null values for DragExpWeek in
computation of the average. The results might be reported as follows:
+------------------+
| avg(DragExpWeek) |
+------------------+
| 3.7500
|
+------------------+
The aggregate function count counts only on the non-null values. To obtain a count of the number of tuples in the relation CurrentBioStudy,
even those with null for some but not all fields, we have * as the
argument of count, as follows:
select count(*) from CurrentBioStudy;
For a count of the number of Rh+ subjects,
select count(*)
from CurrentBioStudy
where RhFactor = '+';
The modifier distinct appears before the column name to compute
the function on only distinct values. Thus, to discover how many different
solvents appear in the ChemExperiment relation, we write the following
statement, where select statement inside the parentheses generates a
temporary table of distinct solvent names:
select count(*) from
(select distinct SolventName
from ChemExperiment);
Sometimes, we group tuples with a common attribute value to perform an aggregate function on the collection. For example, to display the number of subjects in each blood type, grouping by blood type, we display each blood type and a count of the elements in that group, as follows:
select BloodType, count(BloodType)
from CurrentBioStudy
group by BloodType;
Because of the amount of computation involved in executing order or group, the clauses should be used sparingly. Their use can significantly slow database access in a distributed environment. If many such summaries are needed, retrieval of the data from the database with summary processing by a computer program should be considered.
Quick Review Questions |
Besides aggregate functions, SQL has functions that apply to one value (such as a field value) at a time. Table 2 contains a partial list of such functions. These functions can appear in a select clause or a where clause.
Table 2. MySQL functions that apply to one value at a time. Material in square brackets, [ ], is optional.
| Function | Meaning |
| abs(n) | Absolute value of n |
| acos(n) | Arc cosine (inverse cosine of n) |
| asin(n) | Arc sine (inverse sine of n) |
| atan(n) | Arc tangent (inverse tangent of n) |
| concat(s1, s2, ..., sn) | Concatenation of strings s1, s2, ..., sn |
| conv(n, b1, b2) | Convert n from base b1 to base b2 |
| ceiling(n) | Ceiling of n, smallest integer ≥ n |
| cos(r) | Cosine of r, which is in radians |
| cot(r) | Cotangent of r, which is in radians |
| curdate() | Current date; number YYYYMMDD or string 'YYYY-MM-DD' |
| curtime() | Current time; number HHMMSS or string 'HH:MM:SS' |
| database() | Name of current database |
| adddate(d, i) | Date d plus interger i |
| subdate(d, i) | Date d minus interger i |
| dayname(d) | Day of week for date d |
| dayofmonth(d) | Day of month for date d |
| degrees(r) | Degrees corresponding to radians r |
| encrypt(s1, s2) | Password encrypt string s1 using salt s2 |
| exp(p) | ep |
| floor(n) | Floor of n, largest integer ≤ n |
| format(n, d) | Format n with d decimal places |
| hour(t) | Hour of time t |
| if(b, v1, v2) | If b is true, v1, else v2 |
| isnull(e) | 1 (true) if e is null, 0 (false) otherwise |
| log(n) | Natural logarithm of n |
| log10(n) | Common logarithm of n |
| minute(t) | Minute of time t |
| mod(n1, n2) | n1 % n2 |
| month(d) | Number of month for date d |
| monthname(d) | Name of month for date d |
| now() | Current date and time |
| password(s) | Password-encrypted string s |
| pi() | Pi (π) |
| pow(n, p) | np |
| radians(d) | Radians corresponding to degrees d |
| rand([seed]) | Random floating point number between 0 and 1; optional seed seed |
| round(n [, d]) | n rounded to d decimal places or to an integer if no d |
| second(t) | Seconds of time t |
| sin(r) | Sine of r, which is in radians |
| sqrt(n) | Square root of n |
| tan(r) | Tangent of r, which is in radians |
| truncate(n, d) | n truncated to d decimals |
| user() | Current user |
| week(d) | Week of year for date d |
| year(d) | Year for date d |
Suppose the table, mushroom, of a database contains the MushroomId and radius of the cap as well as other information for a number of mushrooms. To estimate the surface area of the top, we compute the area of a circle, πr2, as follows:
select MushroomId, Pi() * Pow(radius, 2)
from mushroom;
The area is computed individually for each value of radius. An alternative to Pow(radius, 2) is to multiply, radius * radius. As this example illustrates, we can use the arithmetic operators +, -, *, /, and % (remainder) as well as the SQL functions.
Quick Review Questions |
Write the entire statement, and click here to view the answer.
The module "Creating and Changing Databases with SQL" discusses table creation, and the module "Updating Data with SQL" covers insertion of data into an existing table. In the present module, we do not duplicate these discussions, but we sometimes do find it convenient to store a table that a select statement generates in a named table. To create such a new named table, we employ the insert command and give the name of the new table into which we place the data. In Example 1, we projected the ChemExperiment table onto the columns ExpNumber and SolventMass and selected a subset of the data involving Benzene. To save these data in a new table, BenzeneTbl, with the same column name as in ChemExperiment, we employ the following statement using insert into that for clarity has the select statement in parentheses:
insert into BenzeneTbl
(select ExpNumber, _SolventMass
from ChemExperiment
where SolventName = 'Benzene' and
SolventMass > 100);
To change the column names or to give column names in ambiguous or unclear situations, we put the names in a list in parentheses after the new table's name. For example, to place the mushroom ids and surface areas into a table, MushroomArea, with column names ID and Area, we employ the following insertion statement:
insert into MushroomArea(ID, Area)
(select MushroomID,Pi() * Pow(radius, 2)
from mushroom);
Quick Review Questions |
1. Consider a database called anthropology with a discovery relation having the following schema:
(ItemID: int, DiscoveryDate: date, longitude: float, latitude: float, condition: { 'EXCELLENT', 'VERYGOOD', 'GOOD', 'POOR', 'VERYPOOR'}, carbon14: float)
Write statements to do each of the following tasks:
a. Use the database
b. View the ItemIDs and descriptions of all items in poor condition.
c. Count the number of items
d. Compute the approximate age of the item as 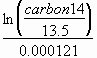
2. For the psychology database of Quick Review Question 4, write a statement to display each event code (EventNumber) and the number of times that event occurs.
3. a. We can compute an estimate of the molecular weight of a solute, as follows, where the masses are in grams:
![]()
Kf is a column in table ChemSolvent, and the other columns are in ChemExperiment. Write a statement to display the experiment number (ExpNumber) and the computed molecular weight for each solvent.
Click here to see the answer.
b. Write a statement to return the estimated molecular weight for the experiment number 37.
Click here to see the answer.
c. Write a statement to query the ChemKnowns relation to return any KnownCompound whose MolecularWeight (g/mole) is within 5 g/mole of the value computed from Part b.
Click here to see the answer.
For each of the following projects performing queries of various databases, keep an online log of your work. Each project contains a file of SQL commands to generate table(s) and load data into the table(s). Save this file in a directory containing your database. Enter (use) the database into which you wish to create the table(s) and insert the data. We can execute the sequence of commands in the file with a command having the following format:
mysql -u username -p < MySQLfile
1. Click on the hyperlinks to display the assignment and to download a command file to create and load a database of Atomic Spectra. (The structure and data are derived by Dr. Orlando Karam from the NIST Atomic Spectra Database.)
2. Click on the hyperlinks to display the assignment and to download a command file to create and load a database on Superfund sites in South Carolina (SC). (The structure and data are derived by Dr. Orlando Karam from the EPA's Superfund (CERCLIS) Database.)
3. Click on the hyperlinks to display the assignment and to download a command file to create and load a database on of star data. (The structure is derived by Dr. Orlando Karam from star.dat by Dr. Dan Welch (see Project 5 of "Introduction to Databases").)
Copyright © 2002, Dr. Angela B.
Shiflet
All rights reserved